Don't be lazy about lazy sequences. 35
Coding with infinite sequences is very powerful, but also very bizarre. If you aren’t careful you can get algorithms that work fine, but are O(N^2) instead of O(N).
Consider the (partial-sums) function that I used in my previous blog on generating pi.
(defn partial-sums [s]
(lazy-seq
(cons (first s) (add-streams (next s) (partial-sums s)))))
This function takes in a list of (a b c…) and returns a list of partial sums (a a+b a+b+c…). Trying to figure out how this function works is a bit mind-bending; at least for me; but here’s how I visualize it.
It adds (next s) to (partial-sums s).
(next s)
|
V
s: (a b c d ...)
(partial-sum s): (a a+b a+b+c ...)
Notice how the vertical columns are the sums that we want. Notice also that each result is the sum of the previous result and the next element of s. So verbally and visually this all makes sense. But algorithmically it can still be challenging to understand. I mean, how do those values get calculated really?
Oh… And I should note… The function above doesn’t work this way at all. It’s actually horrifically inefficient. But I’ll get to that, and to the solution. First things first.
What allows this function to run is lazy-evaluation. All that really means is that an element of a list does not really exist until you ask for it. At that point the program calculates what the element of the list should be and then returns it to you as if it was there all along.
In Clojure, when you build a sequence inside the (lazy-seq) form, it simply defers the execution of the procedures that generate the values of the sequence until those values are requested. Look again at the function above. When you call it, it simply returns immediately without doing anything. The (lazy-seq) form simply short-circuits the execution of the function, deferring it for later.
So when (partial-sums) returns it gives you a sequence, but there’s nothing in it! However, as soon as you ask for the first element, the body of the (partial-sums) function will execute just enough to give you the value of the first element. No other elements are calculated. When you ask for the next value, (partial-sums) will execute again, just enough to give you that value. And so on.
Knowing that, let’s trace the execution.
- We call (partial-sums s) which returns a list (let’s call it ps)
- To get the first element of ps, (partial-sums) is lazily-invoked and simply returns (first s)
- For the second element it returns the first element of the sequence produced by (add-streams (next s) (partial-sums s))
which will be: (+ (first (next s)) (first s)) - For the third element it returns the second element of the added streams, but the element is composed of yet another stream addition invoked by the recursive (partial-sums) So it looks like this:
(+ (first (next (next s)) (+ (first (next s)) (first s))
“Uh… Wait.” I hear you say. “You mean that in order to calculate the third element, you have to add three elements? Didn’t we say that we could add the next element of s to the previous element of the partial sums? Why do we have to do three additions? Why does it seem to be doing this:”
(a b c)
(a b c)
(a b c)
Notice that the vertical columns are the sums we are looking for; but calculating them requires a lot more work than just adding the next value to the previous sum!.
“But wait,” you say again. “I know something about Clojure. Clojure memoizes the list values. Once you ask for a list element the first time, it never has to recalculate it again! So when we get the third element of the result it shouldn’t have to recalculate the second.”
Partly right. Once you lazily evaluate a list element, that element never has to be evaluated again. It’s in the list, and will simply be returned from the list. But let me ask you this: In the function above, where is the list that being asked again? Look closely. There is no partial-sums result that is being asked for a value more than once. Indeed, every time we need a value we create a new (partial-sums) list. So we aren’t taking advantage of the previous values because we’re always creating a new list.
If you’d like to prove this to yourself, you can run this fun little program.
(defn p [a b] (println a '+ b) (+ a b))
(defn add_streams [a b] (map p a b))
(defn partial-sums [s]
(lazy-seq
(cons (first s)
(add_streams (next s) (partial-sums s)))))
(def w (iterate inc 1))
(println (take 5 (partial-sums w)))
Notice how I print every addition in the (p) function. If you run this you’ll get the following result:
(2 + 1 1 2 + 1 3 + 3 3 2 + 1 3 + 3 4 + 6 6 2 + 1 3 + 3 4 + 6 5 + 10 10 15)
The jumble of numbers is evidence that the lazy evaluation is working. As the println marches through the 5 partial sums, it causes each to be evaluated, causing each sum to be printed. Notice how many sums are taken! Ten additions for 5 partial sums. It’ll be 15 for 6, and 21 for 7. Indeed, the number of additions required to calculate ps[n] is equal to ps[n-1]. A little thought will convince you that this is O(n^2).
To reduce this back to O(n), we need to stop creating a new list of partial-sums at each recursion, and use a single copy of the partial-sums result. We can do this by saving the partial sums result in a var, and then using that in the add-streams call.
(defn partial-sums [s]
(def result (lazy-seq
(cons (first s)
(add_streams (next s) result)))) result)
This may bend your brain just a little bit more. We are using the result before we are done calculating it! But that’s ok, since we never use more than has already been calculated…
Running the program with this change yields the following output.
(2 + 1 1 3 + 3 3 4 + 6 6 5 + 10 10 15)
That’s the O(n) behavior we wanted! Each sum is calculated by adding the next element to the previous sum! Hooray!
There’s a lesson here. You don’t get the benefit of lazy sequences unless you use the lazy sequences. Creating a brand new one each time may generate the right answer, but it’s lazy, and can burn a lot of execution cycles.
One problem I have with this solution is the creation of the global var ‘result’. I’m sure there’s a way to create a local result; but I haven’t found it yet. (I tried using various let forms, but I haven’t stumbled upon one that works yet.)
Generating PI in Clojure 57
The SICP book shows a cute algorithm for computing PI using infinite sequences (lazy evaluation). I have adapted it for Clojure and modified it to use Java’s BigDecimal class, so that I can generate arbitrary precision.
First we define a function that generates an “infinite” list of terms of the form 1/1 + 1/3 – 1/5 + 1/7 – ... This is a well known series that very slowly converges on Pi. Notice that I’m using the ‘M’ suffix to denote BigDecimal, and I’m restricting the precision to 300 places. Notice also that I’m using lazy-seq. This function delays the execution of the ‘cons’ term until that part of the list is actually used. This allows the list to appear to be infinite.
(defn pi-summands [n]
(lazy-seq
(cons (with-precision 300 (/ 1M n))
(map - (pi-summands (+ n 2))))))
Next we have two utility functions. The first multiplies the terms of a list by a scale factor. The other adds two lists together producing a list of sums. If the input lists are ‘infinite’, the output lists will also be ‘infinite’.
(defn scale-stream [stream factor] (map (fn [x] (* x factor)) stream)) (defn add-streams [p q] (map + p q))
partial-sums takes a list of terms produces a list of the sums of those terms. Given [a b c] it produces [a a+b a+b+c]. And, again, the lists can be infinite.
(defn partial-sums [s]
(lazy-seq
(cons (first s) (add-streams (next s) (partial-sums s)))))
pi-stream mutiplies the partial-sums of the pi-summands by 4. Turning the summing sequence into 4/1 + 4/3 – 4/5…
(def pi-stream (scale-stream (partial-sums (pi-summands 1)) 4))
A simple squaring function.
(defn square [s] (* s s))
Euler’s transform is a fancy way to average three terms of a +/- sequence. It can dramatically increase the precision of an otherwise slowly converging sequence. The euler-transform function produces a sequence of results from the pi-stream. Again, note the constraint I place on BigDecimal precision.
(defn euler-transform [s]
(let [s0 (nth s 0)
s1 (nth s 1)
s2 (nth s 2)]
(lazy-seq
(cons (with-precision 300 (- s2 (/ (square (- s2 s1))
(+ s0 (* -2 s1) s2))))
(euler-transform (next s))))))
It turns out that you can use Euler’s transform on it’s own results to further increase precision. The make-tableau function arranges the reapplication of a transform so that it can be repeatedly applied to itself.
(defn make-tableau [transform s]
(lazy-seq
(cons s (make-tableau transform (transform s)))))
And now we grab the first element of each repetition.
(defn accelerated-sequence [transform s] (map first (make-tableau transform s)))
A little utility to print the elements of a list.
(defn print-list [s] (doseq [n s] (println n)))And now finally we print the first 150 iterations of the accelerated euler-transformation of the pi sequence.
(print-list (take 150 (accelerated-sequence euler-transform pi-stream)))
The 150th result (the first two lines of which are accurate) 3.14159265358979323846264338327950288419716939 93751058209749445923078164062862089986280348253 25256352154500957038098311477352066337027814620 46050836612955894790973622135628850706785335611 34661971615744147647325427374216175843967838084 09640502874355811103562027043480098593797655792 36344321165429010895M
Scenario Tables for FitNesse 79
Scenario Tables are a very powerful new feature of FitNesse, allowing a whole new level of abstraction in the specification of tests. Scenario tables can be used on any page that uses the Slim test system.
One of the tests among the many acceptance tests for FitNesse itself ensures that certain operations require authentication. For example, if you declare a page to be read-locked, then you should not be able to read that page unless you have logged in.
Here is an example of an old-style FitNesse test that ensures that you can not save a page that is write-locked unless you log in.

Notice the detailed, step by step, programmerish nature of the test. 1. It creates a user with a password. 2. It creates a page that is write-locked. 3. It requests the page without any authentication and expects a 401. 4. It requests the page with bad authentication and expects a 401. 5. It requests the page with good authentication and expects a 303.
This test is not too hard to understand, and any good QA/BA ought to be able to grasp what it is doing. But it is certainly circuitous and indirect. Worse, this algorithm is repeated on a new page for each of fifteen other secure operations, creating a suite of very similar pages. In other words, lots of duplication.
In sweeping through the acceptance tests of FitNesse, I decided to use scenarios to simplify them. My first attempt at this was to adopt a Given/When/Then (BDD) approach. The same kind of approach that you might use with Cucumber of JBehave.

This test is much shorter, easier to read, and gets right to the point. It’s also much less programmerish since it doesn’t mention 401s or 303s. I was able to accomplish this by creating a set of scenarios that look something like the ones below. (They aren’t the exact ones, but you get the idea.)
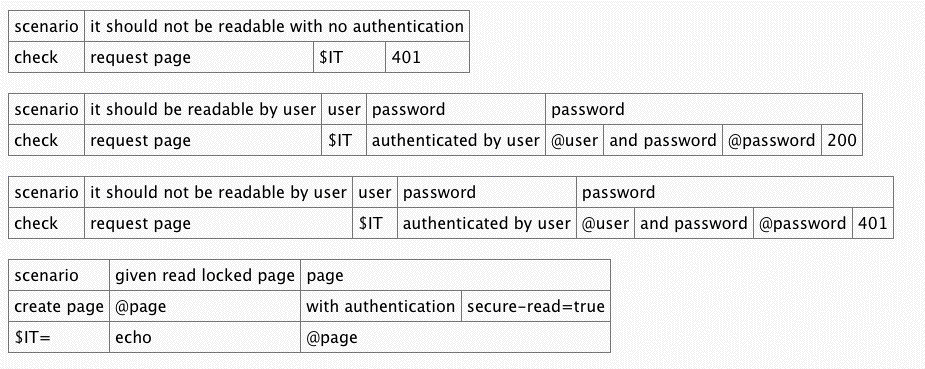
All the programmerish stuff is hidden in the scenarios! That’s nice. If you look closely at the scenarios and substitute them into the test, you can see that the whole test simply turns into something very much like the original test.
Though this is better, we still have a lot of similar pages. The duplication has not been removed.
So then I added a third level of indirection. This one solves all the problems.

It’s hard to imagine a simpler test than this. Instead of a suite of sixteen different tests, I have one single test. The scenario is simply executed once of reach row of the “Operation is authenticated” table.
Here are the scenarios that allowed me to do this.

Once again, if you simply replace the scenarios in each row of the table, you’ll wind up with sixteen tests that look a lot like the original test. But now they are very direct, absurdly simple to read, and are virtually free of programmerish gobblety-gook.
Critics may rightly point out that you can get the same results by simply writing a ColumnFixture that interprets the final table. True, but then you put the burden of test-abstraction on the programmers. What is interesting about the scenario approach is that I was able to reduce the programmerish and highly duplicated tests into a single simple test table without writing any new fixtures!
In other words, programmers can supply a set of APIs, in the form of fixtures, and then competent test engineers can shape the tests appropriately with scenario tables that eventually call the low level fixture APIs while keeping the tests readable and free of duplication.
More Clojure from Uncle Bob JSPS 26
Thanks to all who posted their solutions to the Bowling Game. Just to be contrary, I decided to implement yet another kind of solution. This one clearly shows my OO roots.
(ns bowling-game) (use 'clojure.contrib.test-is) (use 'bowling-game) (defn roll-list [game list] (vec (concat game list))) (defn roll-many [game n pins] (roll-list game (repeat n pins))) (deftest can-create-game (is (not (nil? (new-game))))) (deftest gutter-game-should-score-0 (is (= 0 (score (-> (new-game) (roll-many 20 0)))))) (deftest all-ones-should-score-20 (is (= 20 (score (-> (new-game) (roll-many 20 1)))))) (deftest one-spare (is (= 16 (score (-> (new-game) (roll-list [5 5 3]) (roll-many 17 0)))))) (deftest one_strike (is (= 24 (score (-> (new-game) (roll-list [10 3 4]) (roll-many 16 0)))))) (deftest perfect-game (is (= 300 (score (-> (new-game) (roll-many 12 10)))))) (run-tests 'bowling-game)
And here is the code.
(ns bowling-game)
(defn new-game [] [])
(defn frame-type [[first second]]
(cond
(= 10 first) :strike
(= 10 (+ first second)) :spare
:else :no-mark))
(defmulti frame-size frame-type)
(defmethod frame-size :strike [_] 1)
(defmethod frame-size :spare [_] 2)
(defmethod frame-size :no-mark [_] 2)
(defmulti frame-score frame-type)
(defmethod frame-score :strike [[_ first second]] (+ 10 (+ first second)))
(defmethod frame-score :spare [[_ _ next]] (+ 10 next))
(defmethod frame-score :no-mark [[first second]] (+ first second))
(defn score [game]
(loop [frame 1 rolls game score 0]
(if (> frame 10)
score
(recur (inc frame) (subvec rolls (frame-size rolls)) (+ score (frame-score rolls))))))
Uncle Bob, JSPS: Learning Clojure 118
(JSPS: Just Some Poor Schmuck)
I’m trying to learn Clojure, and I’m finding the effort challenging. Perhaps you can help me.
Programming in Clojure (A derivative of Lisp) requires a certain “inside-out” thinking. I’m finding the combination of the shift in thought process and TDD quite difficult to resolve. So I thought I’d ask for your help.
Below is the Bowling Game written in Clojure complete with unit tests. I’m not at all pleased with the result. The tests, especially, look bizzare and backwards to me.
Please post your own solutions to this so that we can all compare and contrast them.
Tests
(ns bowling-game)
(use 'clojure.contrib.test-is)
(use 'bowling-game)
(defn roll-list [game list]
(if (empty? list)
game
(roll-list (roll game (first list)) (rest list))
))
(defn roll-many [game n pins]
(loop [i n g game]
(if (zero? i)
g
(recur (dec i) (roll g pins)))))
(defn gutter-game [game] (roll-many game 20 0))
(deftest can-create-game
(is (not (nil? (new-game)))))
(deftest gutter-game-should-score-0
(is (= 0 (score (gutter-game (new-game))))))
(deftest all-ones-should-score-20
(is (= 20 (score (roll-many (new-game) 20 1)))))
(deftest one-spare
(is (= 16 (score
(roll-many
(roll-list (new-game) [5 5 3])
17 0)))))
(deftest one_strike
(is (= 24 (score
(roll-many
(roll-list (new-game) [10 3 4])
16 0)))))
(deftest perfect-game
(is (= 300 (score (roll-many (new-game) 12 10)))))
(run-tests 'bowling-game)
Code
(ns bowling-game)
(defn new-game [] [])
(defn next-two-balls [rolls]
(+ (rolls 0) (rolls 1)))
(defn score-strike [rolls]
[1 (+ 10 (+ (rolls 1) (rolls 2)))])
(defn score-spare [rolls]
[2 (+ 10 (rolls 2))])
(defn score-no-mark [rolls]
[2 (next-two-balls rolls)])
(defn score-next-frame [rolls]
(if (= 10 (first rolls))
(score-strike rolls)
(if (= 10 (next-two-balls rolls))
(score-spare rolls)
(score-no-mark rolls))))
(defn score [game]
(loop [frame 1 rolls game score 0]
(if (> frame 10)
score
(let [frame-score (score-next-frame rolls)]
(recur (inc frame) (subvec rolls (frame-score 0)) (+ score (frame-score 1)))))))
(defn roll [game pins]
(conj game pins))
The Rush 60
There’s nothing like the feeling of achievement when you get a complex software system working. It’s the feeling of the hunter making a hard fought kill. By the sheer power of your intellect you have imposed your will upon inanimate nature, and forced it to do your bidding. You feel the rush of power, the satisfaction of victory. You are the master!
That’s the good news.
The bad news is that you’ve made a mess of things along the way.
This is inevitable. It takes a great deal of focus and endurance to get a system working just right. While you are consumed by that focus, you have little room for niceties like small functions, nice names, decoupling, and cleanliness.
My apprentice and I just finished achieving a major milestone in FitNesse. It used to be that each new release of FitNesse was contained in a zip file that had all the files and directories laid out just perfectly. This is great for a brand new installation, but doesn’t work so well when you are upgrading. What we managed to get working last night was the ability for FitNesse to self-install from it’s jar file. Now, whether you are installing for the first time, or just upgrading, FitNesse will install itself into your environment appropriately.
If you’ve ever written a self-install like this, you know there are lots of niggling little details to attend to. While the problem is conceptually simple, the realization is a maze of complexity.
Last night, with dinner waiting on the table and getting cold, we got the last little problem licked, and saw the whole self-installation work as we wanted. We congratulated each other with a high-five, and then went upstairs to eat a well-deserved meal. Later that evening I went down to the office and checked in the code.
This morning I woke up, and while in the shower, I realized that we had a lot of work left to do. We need to go back over all that code and clean it up. I’m sure we left a swath of detritus while on the hunt.
The rush of victory should never be confused with the cold and crystalline concept of done. Once you get your systems to work, you still have to go back and clean up the wreckage left behind by the victorious battle. You are not done until the victorious code has been cleaned, polished, and oiled.
Clean Code and Battle Scarred Architecture 89
If you go here you’ll see that I struggle to keep the CRAP out of FitNesse. Despite the whimsical name of this metric (which I take a perverse delight in), I find it to be remarkably useful.
CRAP is a metric that is applied to each function in the system. The formula for CRAP is: CRAP = comp(f)2. X (1 – cov(f)/100)3. + comp(f)
Where comp(f) = the cyclomatic complexity of the function f. and cov(f) = the unit test coverage of function f.
So a function’s CRAP will be small iff the cyclomatic complexity is low and the test coverage is high. CRAP will be huge if cyclomatic complexity is high, and there is no coverage.
What does this have to do with architecture? Read on…
I work very hard to keep the ratio of crappy methods near .1%. Of the 5643 methods in FitNesse, only 6 are crappy, and five of those I have no control over.
If you study the graph you can see how quickly I react to even the slightest uptick in crap. I don’t tolerate it because it means that either I’ve got a horrifically complex method that needs to be refactored, or (and this is far more likely) I’ve got a method that isn’t sufficiently tested.
Why am I so fastidious about this? Why am I so concerned about keeping the crap out of FitNesse? The reason is pretty simple. It’s the least I can do.
If you look inside of FitNesse, you’ll find that there are lots of structures and decisions that don’t seem to make a lot of sense at first reading. There are complexities and abstractions that will leave you shaking your head.
For example. We generate all our HTML in code. Yes, you read that correctly. We write Java code that constructs HTML. And yes, that means we are slinging angle brackets around.
To be fair, we’ve managed to move most of the angle bracket slingers into a single module that hides the HTML construction behind an abstraction barrier. This helps a lot, but cripe who would sling angle brackets when template system are so prevalent? I hope nobody. But FitNesse was not conceived at a time when template systems made sense (at least to us).
Fear not, I am working through the Fitnesse code replacing the HTML generation with Velocity templates. It’ll take some time, but I’ll get it done. The point is, that just like every other software system you’ve seen, FitNesse is a collection of historical compromises. The architecture shows the scars of many decisions that have since had to be reversed or deeply modified.
What does this have to do with CRAP? Simply this. The battle scarred architecture is something that will never really go away. I can stop the bleeding, and disinfect the wounds, but there will always be evidence of the battle.
That scarring makes the system hard to understand. It complicates the job of adding features and fixing bugs. It decreases the effectiveness of the developers who work on FitNesse. And though I work hard to massage the scars and bandage the wounds, the war goes on.
But I can keep the CRAP out! I can keep the code so clean and simple at the micro level, that the poor folks who try to make sense out of the macro scale aren’t impeded by huge deeply nested functions that aren’t tested!
Think of it this way. CRAP is disease at the cellular level. CRAP is a rot so pervasive that it can infest every nook and cranny of the system. My system may have scars, but it’s not diseased! In fact, despite the evidence of battles long past, the FitNesse code is very healthy.
And I aim to keep it that way.
Why the sea is boiling hot 126
In my keynote at the Rails Conference last Wednesday, I spoke about What Killed Smalltalk and could it Kill Ruby Too?. In this keynote, as is my wont, I spoke about the need for our industry to define itself as a profession, and for us to define ourselves as professionals. I closed the keynote with this statement: “Professionalism does not mean rigid formalism. Professionalism does not mean adhering to beaurocrasy. Professionalism is honor. Professionalism is being honest with yourself and disciplined in the way you work. Professionalism is not letting fear take over.”
David Heinemeier Hansson, inventor of Rails, and affectionately referred to as @dhh has posted a blog in response in which he asserts that we need artists as well as professionals, and draws a dichotomy between the two. The dichotomy is a false one…
We are a community of artisans. We make things with our hands! We all strive, like @dhh, to make things of great beauty and utility. In no way, and by no means, do I wish to assail that artistry. Indeed, my hope is to free it. I want to convince all programmers that the desire for, and the pursuit of beauty is the way you satisfy your customers. The only way to go fast, is to go well.
I want developers to take pride in their work. I also want them to take pride in the way that they work. I want them to be able to look back on the last few days, weeks, and months, and be able to say to themselves, “I made something beautiful, and I made it well.”
We are a quirky lot. Some of us wear faded jeans with yesterday’s spaghetti on them. Others wear T-shirts that have PI wrapped around them. There are beards, tatoos, tongue-studs and hair in all shapes and colors. There are hawaiian shirts and sandals. There are jackets and ties and sometimes even suits. Some of us speak carefully. Some of us drop F-bombs at a whim. Some of us are liberal, and some are conservative. Some of us relish in being seen, and some of us are glad to be overlooked. In short, we are a group of diverse people who are drawn together by our common passion for code.
There is nothing wrong with this diversity. Indeed it’s healthy. The fact that we all think differently about styles, language, appearance, and values means that there are a zillion different ways that we can learn from each other. And in that learning grows the seed of our profession.
So @dhh is right, at least about the diversity. We should all relish the opportunity to share ideas with people who think differently than we do. But @dhh is wrong when he draws the dichotomy between artists and engineers. Every engineer is an artist, and every artist is an engineer. Every engineer strives for elegance and beauty. Every artist has the need to make their art actually work. The two are inextricably tied. You cannot be one without also being the other.
Now, certainly there are environments where the engineering side of things is emphasized over the artistry side. In extreme cases the artistry is repressed into near non-existence. Such places are soul-searing hell-holes that every programmer should strive to escape (or for the brave: change from within!) Indeed, @dhh implies that he worked in such places and found he was “faking [his] way along in this world.” I completely understand that.
But then @dhh makes his biggest mistake. He equates the professionalism I was talking about in my keynote with those repressive environments. He seems to think that professionalism and artistry are mutually exclusive. That wearing a green band means you give up on beauty. That discipline somehow saps programmer happiness.
But remember what I said when I closed my keynote: “Professionalism does not mean rigid formalism. Professionalism does not mean adhering to beaurocrasy. Professionalism is honor. Professionalism is being honest with yourself and disciplined in the way you work. Professionalism is not letting fear take over.”
This is not a complete definition; but it will serve for my current purposes. Because, you see, I made a big mistake during that keynote. And it is in how we deal with our own errors that the claim of professionalism is most frequently, and most thoroughly tested.
In my keynote I used a metaphor to link hormones and languages. I said that C++ was a testosterone language, but Java was an estrogen language. And then I used the word “insipid” to describe Java.
Now clearly C++ and testosterone have very little in common. My use of this metaphor was an oratory device – a joke. As far as the operation of that device is concerned, it was a success. The vast majority of the audience laughed, demonstrating to me that they were a) listening and b) understanding and c) open.
There is a kind of artistry in making oratory devices like this, and I take a certain amount pride in it. Such devices need to be timed appropriately, delivered skillfully, and used to gauge the audience. They can help to turn virtually any dry topic into a compelling speech.
On the other hand, the construction of this device had a significant flaw. I had equated women with weakness. This was not intentional. I do not think of women as weak. But there it was: Estrogen === Insipid. If you were a woman in that audience, how could you come to any conclusion other than “Uncle Bob thinks women are weak.”
How did I make this error? Lack of discipline. I did not test this keynote adequately. I should at least have run it past my wife! I mis-engineered my art! (Or perhaps my engineering was artless <grin>).
Within minutes of concluding my talk, the complaints appeared on twitter. Women who had been offended and hurt by the remark were tweeting their dissatisfaction. Some men were joining them.
There were two ways I could have responded to this. I could have asserted that these people were just being too sensitive; that they should have realized that this was just an oratory device and that I didn’t mean any harm; that they should just recognize me for who I am and not get so hung up in their own fears and values.
But I think that reaction would have been unprofessional. Why? Because it would have been dishonest. The truth was that this was just a stupid mistake. I built the device badly. I executed the device without testing it properly. I screwed up; and I needed to own up that. So I immediately tweeted apologies to those concerned and ate an appropriate amount of humble pie.
The reason I told you this story (at the risk of sounding somewhat self-aggrandizing) is so that I could use it to help define professionalism. The construction of my oratory device was unprofessional. I should have tested it better. I should have realized the danger of using gender comparisons and taken greater care with their use. I could have done better.
We professionals aren’t prefect. We all make mistakes. We recover from those mistakes by owning up to them as mistakes. We do not cover those mistakes by claiming that everyone else is wrong.
Confronting your mistakes and taking appropriate action is a discipline. It is a discipline of honor and self-honesty. It is a demonstration that we do not let the fear of our own errors take us over.
The Scatology of Agile Architecture 85
One of the more insidious and persistent myths of agile development is that up-front architecture and design are bad; that you should never spend time up front making architectural decisions. That instead you should evolve your architecture and design from nothing, one test-case at a time.
Pardon me, but that’s Horse Shit.
This myth is not part of agile at all. Rather it is an hyper-zealous response to the real Agile proscription of Big Design Up Front (BDUF). There should be no doubt that BDUF is harmful. It makes no sense at all for designers and architects to spend month after month spinning system designs based on a daisy-chain of untested hypotheses. To paraphrase John Gall: Complex systems designed from scratch never work.
However, there are architectural issues that need to be resolved up front. There are design decisions that must be made early. It is possible to code yourself into a very nasty cul-de-sac that you might avoid with a little forethought.
Notice the emphasis on size here. Size matters! ‘B’ is bad, but ‘L’ is good. Indeed, LDUF is absolutely essential.
How big are these B’s and L’s? It depends on the size of the project of course. For most projects of moderate size I think a few days ought to be sufficient to think through the most important architectural issues and start testing them with iterations. On the other hand, for very large projects, I seen nothing wrong with spending anywhere from a week to even a month, thinking through architectural issues.
In some circles this early spate of architectural thought is called Iteration 0. The goal is to make sure you’ve got your ducks in a row before you go off half-cocked and code yourself into a nightmare.
When I work on FitNesse, I spend a lot of time thinking about how I should implement a new feature. For most features I spend an hour or two considering alternative implementations. For larger features I’ve spent one or two days batting notions back and forth. There have been times when I’ve even drawn UML diagrams.
On the other hand, I don’t allow those early design plans to dominate once I start TDDing. Often enough the TDD process leads me in a direction different from those plans. That’s OK, I’m glad I made those earlier plans. Even if I don’t follow them they helped me to understand and constrain the problem. They gave me the context to evaluate the new solution that TDD helped me to discover. To paraphrase Eisenhower: Individual plans may not turn out to be helpful, but the act of planning is always indispensable.
So here’s the bottom line. If you are working in an Agile team, don’t feel guilty about taking a day or two to think some issues through. Indeed, feel guilty if you don’t take a little time to think things through. Don’t feel that TDD is the only way to design. On the other hand, don’t let yourself get too vested in your designs. Allow TDD to change your plans if it leads you in a different direction.
Crap Code Inevitable? Rumblings from ACCU. 368
I gave the opening Keynote at ACCU 2009 on Wednesday. It was entitled: The Birth of Craftsmanship. Nicolai Josuttis finshed the day with the closing keynote: Welcome Crappy Code – The Death of Code Quality. It was like a blow to the gut.
In my keynote I attempted to show the historical trajectory that has led to the emergence of the software craftsmanship movement. My argument was that since the business practices of SCRUM have been widely adopted, and since teams who follow those practices but do not follow the technical practices of XP experience a relentless decrease in velocity, and since that decrease in velocity is exposed by the transparency of scrum, then if follows that the eventual adoption of those technical XP practices is virtually assured. My conclusion was that Craftsmanship was the “next big thing” (tm) that would capture the attention of our industry for the next few years, driven by the business need to increase velocity. (See Martin Fowler’s blog on Flaccid Scrum) In short, we are on a trajectory towards a higher degree of professionalism and craftsmanship.
Nicolai’s thesis was the exact opposite of mine. His argument was that we are all ruled by marketing and that businesses will do whatever it takes to cut costs and increase revenue, and therefore businesses will drive software quality inexorably downward. He stipulated that this will necessarily create a crisis as the defect rates and deadline slips increased, but that all attempts to improve quality would be short lived and followed by a larger drive to decrease quality even further.
Josuttis’ talk was an hour of highly depressing rhetoric couched in articulate delivery and brilliant humor. One of the more memorable moments came when he playacted how a manger would respond to a developer’s plea to let them write clean code like Uncle Bob says. The manager replies: “I don’t care what Uncle Bob says, and if you don’t like it you can leave and take Uncle Bob with you.”
One of the funnier moments came when Josuttis came up with his rules for crap code, one of which was “Praise Copy and Paste”. Here he showed the evolution of a module from the viewpoint of clean code, and then from the viewpoint of copy-paste. His conclusion, delivered with a lovely irony, was the the copy-paste solution was more maintainable because it was clear which code belonged to which version.
It was at this point that I thought that this whole talk was a ribald joke, an elaborate spoof. I predicted that he was about to turn the tables on everyone and ringingly endorse the craftsmanship movement.
Alas, it was not so. In the end he said that he was serious about his claims, and that he was convinced that crap code would dominate our future. And then he gave his closing plea which went like this:
We finally accepted that requirements change, and so we invented Agile.
We must finally accept that code will be crap and so we must ???
He left the question marks on the screen and closed the talk.
This was like a blow to the gut. The mood of the conference changed, at least for me, from a high of enthralled geekery, to depths of hoplessness and feelings of futile striving against the inevitable. Our cause was lost. Defeat was imminent. There was no hope.
Bulls Bollocks!
To his credit, there are a few things that Josuttis got right. There is a lot of crap code out there. And there is a growing cohort of crappy coders writing that crap code.
But the solution to that is not to give up and become one of them. The solution to that is to design our systems so that they don’t require an army of maintainers slinging code. Instead we need to design our systems such that the vast majority of changes can be implemented in DSLs that are tuned to business needs, and do not require “programmers” to maintain.
The thing that Josuttis got completely wrong, in my mildly arrogant opinion, is the notion that low quality code is cheaper than high quality code. Low quality code is not cheaper; it is vastly more expensive, even in the short term. Bad code slows everyone down from the minute that it is written. It creates a continuous and copious drag on further progress. It requires armies of coders to overcome that drag; and those armies must grow exponentially to maintain constant velocity against that drag.
This strikes at the very heart of Josuttis’ argument. His claim that crappy code is inevitable is based on the notion that crappy code is cheaper than clean code, and that therefore businesses will demand the crap every time. But it has generally not been business that has demanded crappy code. Rather it has been developers who mistakenly thought that the business’ need for speed meant that they had to produce crappy code. Once we, as professional developers, realize that the only way to go fast is to create clean and well designed code, then we will see the business’ need for speed as a demand for high quality code.
My vision of the future is quite different from Josuttis’. I see software developers working together to create a discipline of craftsmanship, professionalism, and quality similar to the way that doctors, lawyers, architects, and many other professionals and artisans have done. I see a future where team velocities increase while development costs decrease because of the steadily increasing skill of the teams. I see a future where large software systems are engineered by relatively small teams of craftsmen, and are configured and customized by business people using DSLs tuned to their needs.
I see a future of Clean Code, Craftsmanship, Professionalism, and an overriding imperative for Code Quality.